/** * Constructs an empty <tt>HashMap</tt> with the default initial capacity * (16) and the default load factor (0.75). */ public HashMap() { this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted }
单纯的new HashMap(),只是设定了满载率,并未设定别的参数,满载率为0.75
1 2 3 4 5
// (The javadoc description is true upon serialization. // Additionally, if the table array has not been allocated, this // field holds the initial array capacity, or zero signifying // DEFAULT_INITIAL_CAPACITY.) int threshold;
阈值初始是未赋值
1 2 3 4
/** * The default initial capacity - MUST be a power of two. */ static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
默认容积是16
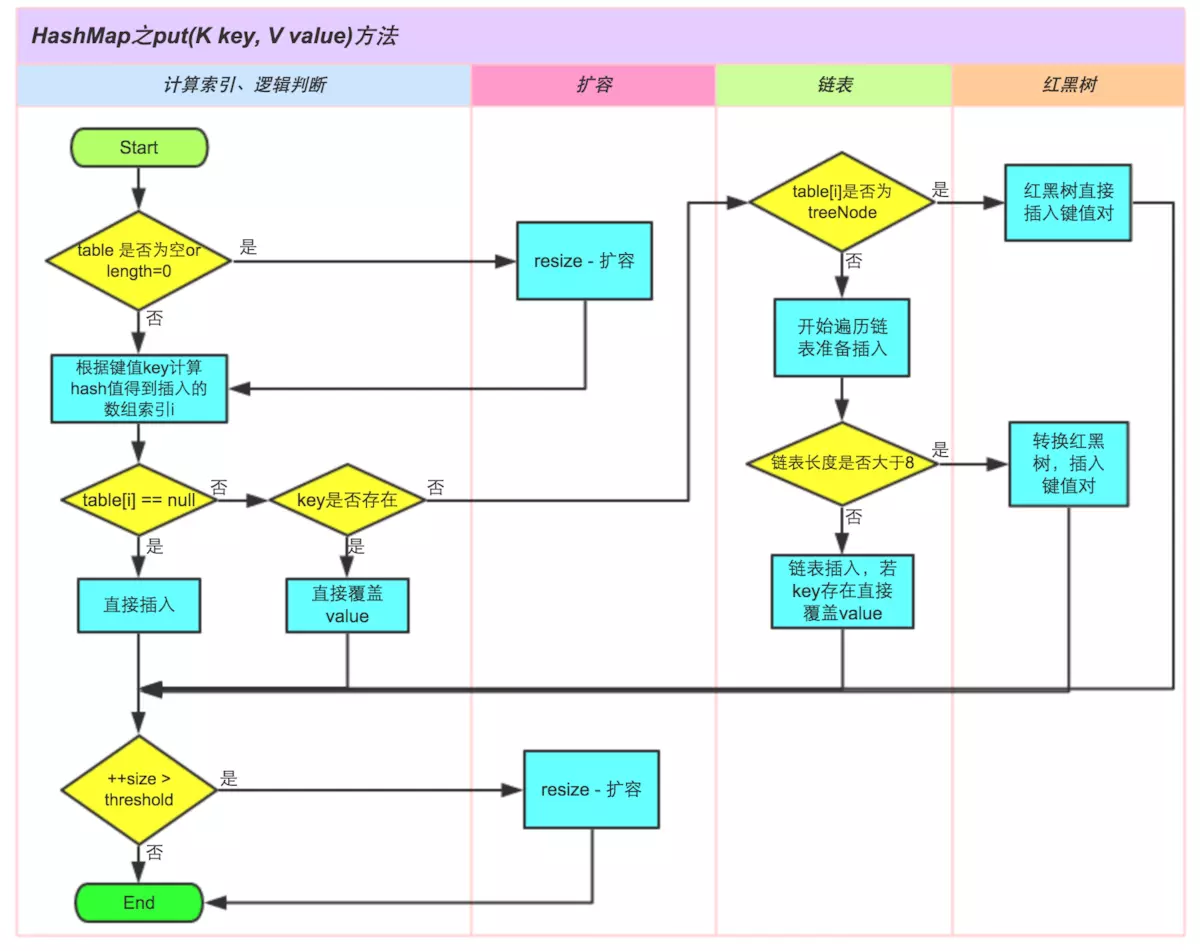
put(K key, V value)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
/** * Associates the specified value with the specified key in this map. * If the map previously contained a mapping for the key, the old * value is replaced. * * @param key key with which the specified value is to be associated * @param value value to be associated with the specified key * @return the previous value associated with <tt>key</tt>, or * <tt>null</tt> if there was no mapping for <tt>key</tt>. * (A <tt>null</tt> return can also indicate that the map * previously associated <tt>null</tt> with <tt>key</tt>.) */ public V put(K key, V value) { return putVal(hash(key), key, value, false, true); }
put方法调用的是
1 2 3 4 5 6 7 8 9 10 11 12
/** * Implements Map.put and related methods * * @param hash hash for key * @param key the key * @param value the value to put * @param onlyIfAbsent if true, don't change existing value * @param evict if false, the table is in creation mode. * @return previous value, or null if none */ final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict)
/** * Computes key.hashCode() and spreads (XORs) higher bits of hash * to lower. Because the table uses power-of-two masking, sets of * hashes that vary only in bits above the current mask will * always collide. (Among known examples are sets of Float keys * holding consecutive whole numbers in small tables.) So we * apply a transform that spreads the impact of higher bits * downward. There is a tradeoff between speed, utility, and * quality of bit-spreading. Because many common sets of hashes * are already reasonably distributed (so don't benefit from * spreading), and because we use trees to handle large sets of * collisions in bins, we just XOR some shifted bits in the * cheapest possible way to reduce systematic lossage, as well as * to incorporate impact of the highest bits that would otherwise * never be used in index calculations because of table bounds. */ static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }